Attention
Attention
트랜스포머의 기반이 되는 어탠션 매커니즘
seq2seq 모델의 문제
- 하나의 고정된 크기의 벡터에 모든 정보를 압축하기 때문에 정보 손실이 일어난다.
- RNN이므로 vanishing gradient 존재
Attention idea
- 디코더에서 출력 단어를 예측하는 매 time step마다 인코더에서 전체 입력 문장을 다시 한 번 참고한다.
- 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)한다.
Attention Function
어텐션 함수는 딕셔너리처럼 Key-Value로 구성되는 자료형이다.
키를 통해서 맵핑된 값을 찾아낼 수 있다는 특징이 있다.
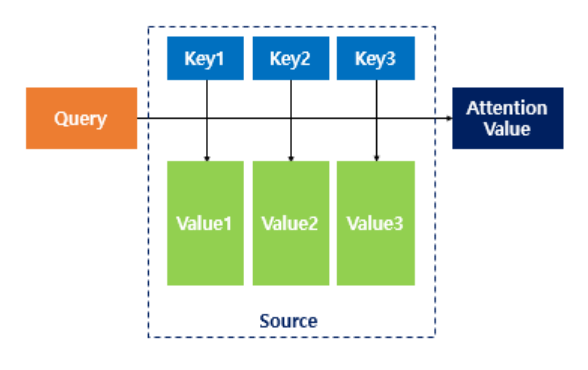
Attention(Q, K, V) = Attention Value
- 주어진 ‘쿼리(Query)’에 대해서 모든 ‘키(Key)’와의 유사도를 각각 구한다.
- 유사도를 키와 맵핑되어있는 각각의 ‘값(Value)’에 반영한다.
- 유사도가 반영된 ‘값(Value)’을 모두 더해서 리턴한다.
i. Q = Query : t 시점의 디코더 셀에서의 은닉 상태
ii. K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
iii. V = Values : 모든 시점의 인코더 셀의 은닉 상태들
dot porduct attention
seq2seq에서 사용되는 어텐션
다른 어텐션과 매커니즘은 유사하다.
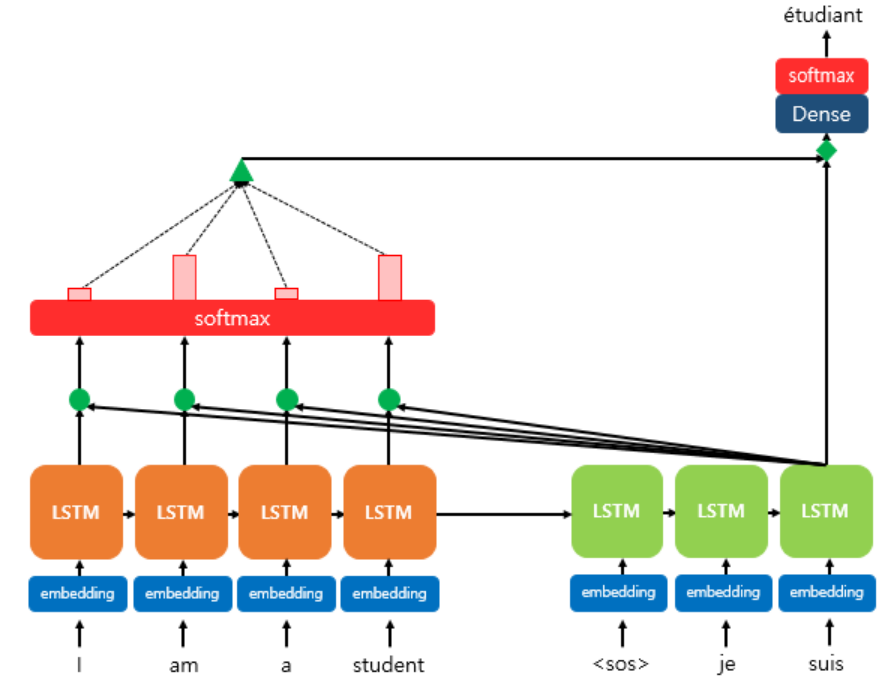
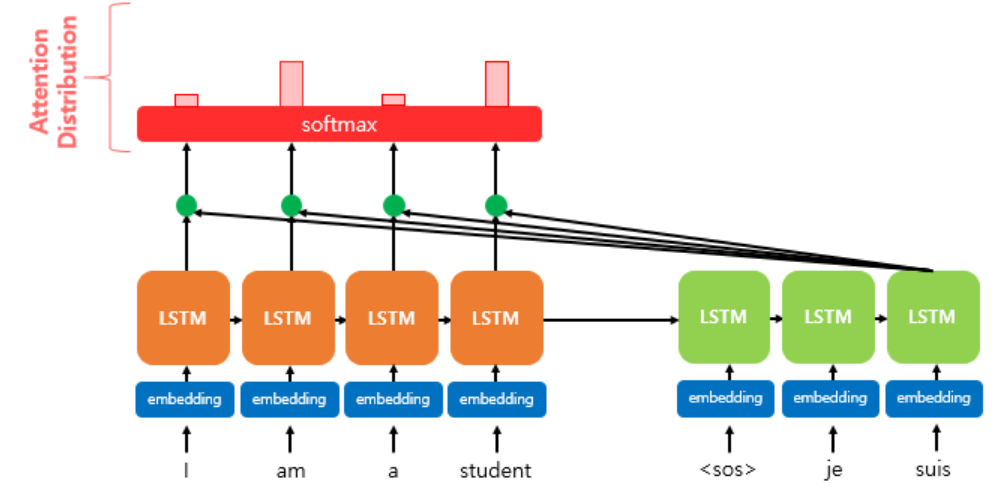
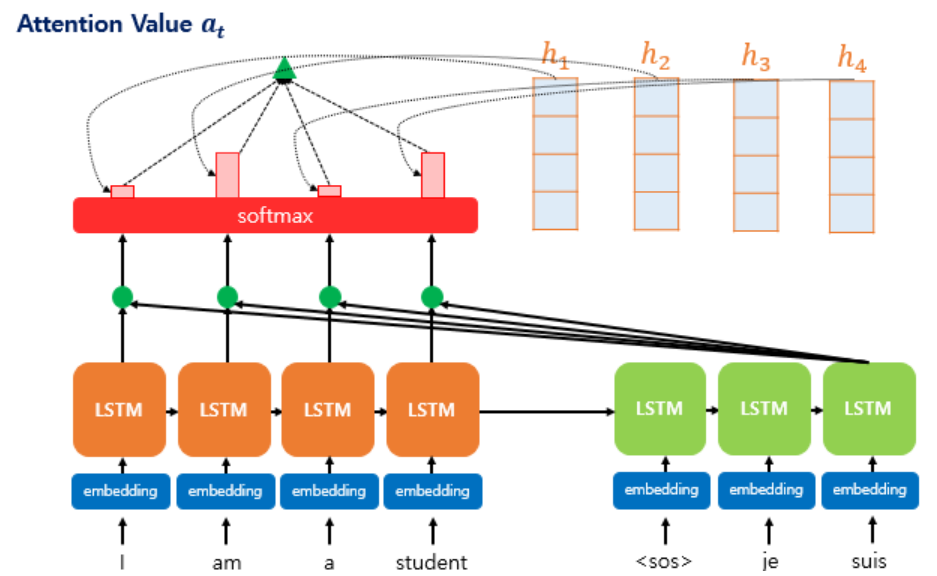
디코더의 세 번째 LSTM셀에서 출력 단어를 예측할 때 어텐션 매커니즘을 사용하는 것을 보여준다.
-
디코더의 첫번째와 두 번쨰LSTM셀은 이미 어텐션 매커니즘을 통해 $je, suis$를 예측하는 과정을 거쳤다고 하자
-
디코더의 세 번째LSTM셀은 출력 단어를 예측하기 위해서 인코더의 모든 입력 단어들의 정보를 다시 한번 참고한다.
-
인코더의 소프트맥스 함수는 인코더의 단어가 각각 출력 단어를 예측할 때 얼마나 도움이 되는지를 수치화한 것이다.
-
이를 하나의 정보로 담어서 디코더로 전송한다.
Attention Score
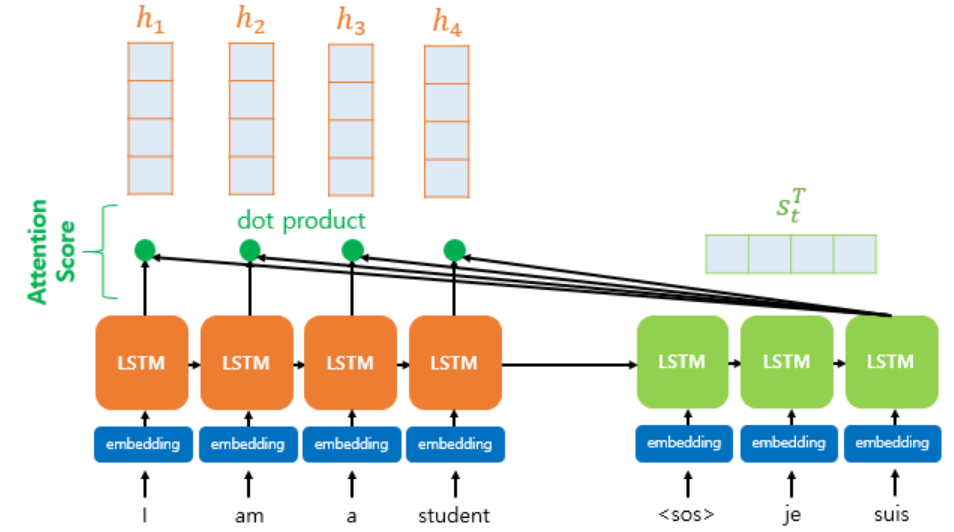
- 인코더의 타임 스텝을 각각 $1,2,…,N$
- 인코더의 은닉 상태(hidden state)를 각각 $h_1, h_2, … h_N$
- 디코더의 현재 시점(time step) t에서의 디코더의 은닉 상태(hidden state)를 $s_t$
- 인코더의 은닉 상태와 디코더의 은닉 상태의 차원이 같다고 가정
- 인코더의 은닉 상태와 디코더의 은닉 상태가 동일하게 차원이 4
디코더의 현재 타입스텝에서 필요한 입력값
- 이전 시점인 $t-1$의 은닉 상태
- 이전 시점 $t-1$의 출력 단어
- 어텐션 매커니즘 에서는 어텐션 값(attention value)을 추가고 필요로 한다.
- attention value를 $a_t$라 하자
Attention Score Value
-
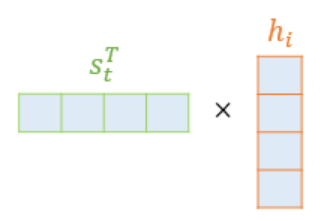
$s_t$를 전치(transpose)하고 각 은닉 상태와 내적(dot product)을 수행
- $s_t$ : 디코더의 은닉 상태
-
모든 어텐션 스코어 값은 스칼라값이다.
-
$s_t$과 인코더의 i번쨰 은닉상태의 어텐션 스코어 계산
-
어텐션 스코어 함수
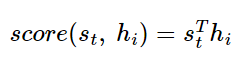
-
-
모든 어텐션 스코어 값을 $e^t$라고 하자
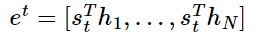
Attention Distribution 어텐션 분포
-
$e^t$에 소프트맥스 함수를 적용해서 모든 값을 더해주면 합이 1인 확률분포를 얻을 수 있다.
- $e^t$는 어텐션 스코어를 모두 모은 값
-
이 확률 분포를 어텐션 분포라고 한다.
-
각각의 값을 어텐션 가중치(Attention Weight)라고 한다.
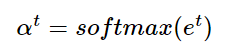
Attention value 어텐션 값
어텐션 가중치와 은닉 상태를 가중합해서 구한다.
-
각 인코더의 은닉 상태와 어텐션 가중치값들을 곱하고 최종적으로 더한다.
-
가중합을 진행한다.
-
어텐션 함수의 출력값인 어텐션 값 $a_t$
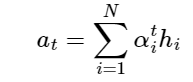
-
어텐션 값 $a_t$는 인코더의 문맥을 포함하고 있으므로 context vector라고도 한다.
- seq2seq에서의 context vector와는 다르다.
- seq2seq에서는 인코더의 마지막 은닉상태를 뜻한다.
Concatenate
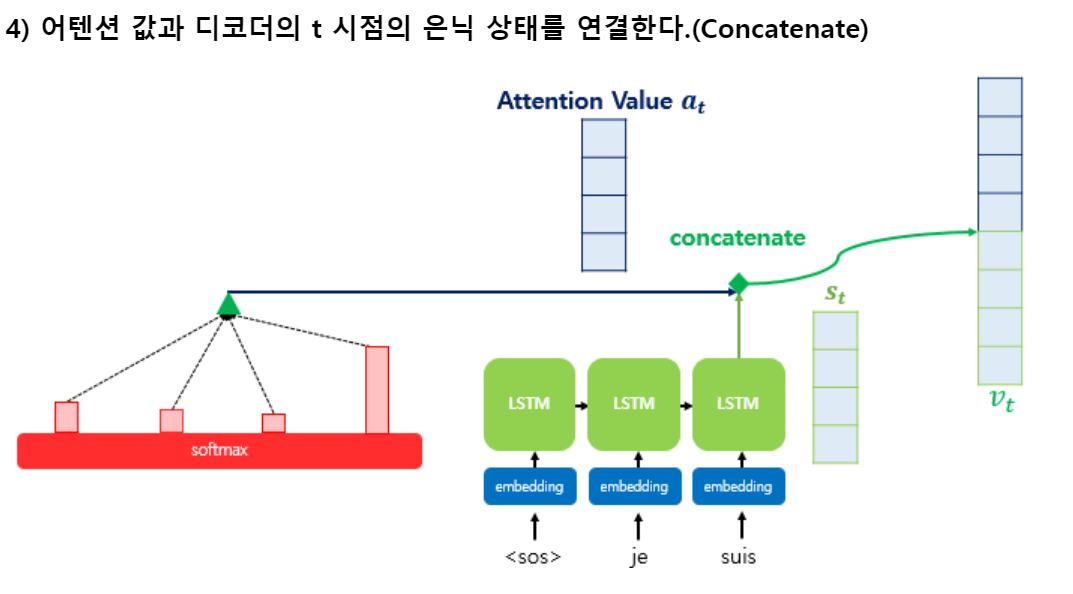
-
어텐션 값이 구해지면 어텐션 메커니즘은 $a_t, s_t$를 결합하여 하나의 벡터로 만드는 작업을 한다.
- 만들어진 벡터를 $v_t$라 하자
- $v_t$를 $\hat y$의 예측 연산의 입력으로 사용한다.
- 인코더로부터 얻은 정보로 $\hat y$의 예측 성능을 높힌다.
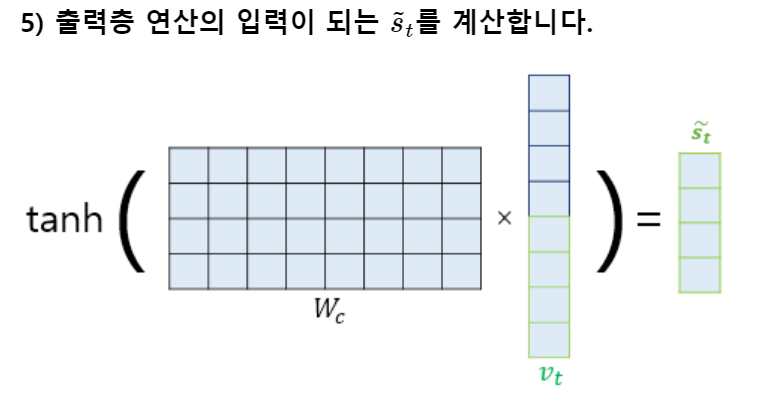
- vt를 바로 출력층으로 보내기 전에 신경망 연산을 한 번 더 추가한다.
- 가중치 행렬과 곱한 후에 $tanh$ 함수를 지나도록 한다.
- 출력층 연산을 위한 새로운 벡터인 $\tilde{s_t}$를 얻는다.
- 어텐션 메커니즘을 사용하지 않는 seq2seq에서는 출력층의 입력이 t시점의 은닉 상태인 $s_t$이다.
- 어텐션 메커니즘에서는 출력층의 입력이 $\tilde{s_t}$가 된다.
$\tilde{s_t}$를 출력층의 입력으로 사용한다. \(W_c: 가중치 \ b_c:편향 \\ \tilde{s_t}=tanh(W_c[a_t:s_t]+b_c) \\ \hat y_t=Softmax(W_y\tilde{s_t}+b_y)\)
가중합
가중합(weighted sum)이란 복수의 데이터를 단순히 합하는 것이 아니라 각각의 수에 어떤 가중치 값을 곱한 후 이 곱셈 결과들을 다시 합한 것을 말한다
